
At .Conf 2018, Splunk announced a new deployment methodology, SmartStore. The new SmartStore indexer capability allows you to use S3 API to store indexed data as remote objects. While this is extremely interesting for Splunk Cloud customers, as it is touted by the marketing hype to significantly lower deployment costs, it is a big departure from the traditional Splunk data tiering approach and introduces new architectural considerations from an infrastructure stand point that may be a bit lost in the marketing fanfare. So let’s take a look at what it is, how it works, and the reasons why an enterprise should or should not adopt it.
In a sense, this is an evolution of decoupling your compute from storage… Something we’ve been a major fan of for quite some time! Don’t believe us? Well here is the 2015 Splunk .conf presentation from Cory on the very topic 3 years ago!
But I digress, here’s how the current Splunk data tiering works using the standard Splunk Hot / Warm / Cold bucket vocabulary:
Hot Bucket – the log file that is currently opened for writing. This lives in $HomePath with Warm Buckets
Warm Bucket – read only log files that are no longer written to. They Live in $HomePath with Hot Buckets. Most searches happen across Hot / Warm Buckets.
Cold Bucket – Data that has been tiered out of $HomePath. Can be hosted via File storage (NFS / CIFS).

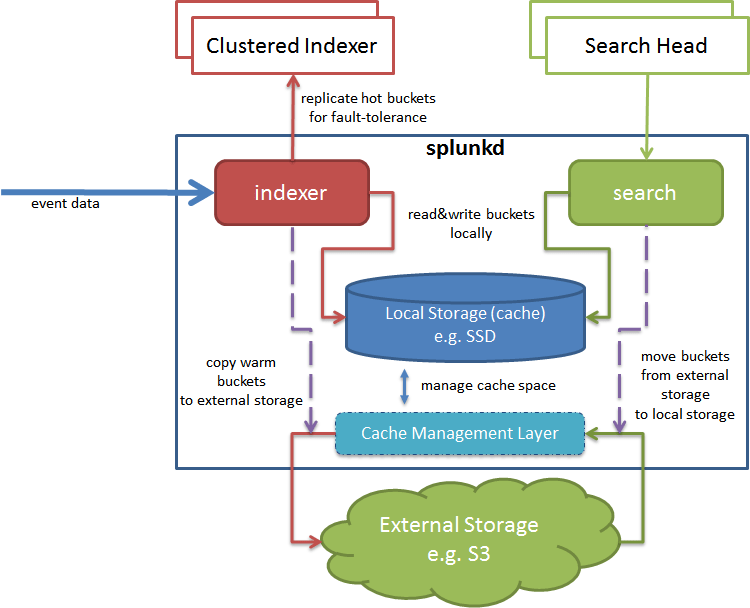
The new SmartStore architecture differs by replacing cold with a remote storage tier via S3 as the aged tier and using hot and warm for local store and introduces a new cache manager for localizing data that may have aged to the remote store. The cache manager handles the copies of data between local and remote storage. You could think of it as the “Tiering Captain”. Let’s you have a smaller footprint of SSD, “hot tier” storage and a larger footprint of the lower cost S3 object store. You can enable SmartStore for all of your indexes or just individual indexes.

Tiering Data
Under SmartStore, your Hot Bucket is now your Cache store. Once your log file rolls from Hot to Warm, a copy will actually get moved into the S3 data store. You will also have a copy on the local cache. The copy of the warm data on the local cache will eventually be evicted from the local cache.
Keep in mind though, your S3 data store will always keep a copy of the Warm bucket, regardless of if it gets copied back to local cache or not. Warm buckets may be copied back into local cache if it is currently or was recently participating in a search as well. Cold Buckets aren’t really in existence now, since your warm data can reside in S3 and a copy in local cache as well. Data still has the option to roll from Warm to Frozen still, and thawing the data will place it back into local cache storage.
Cache Manager
It sounds like the cache manager is really where the rubber meats the road in this deployment. So what do we know about how it behaves? Since 97% of searches only look back 24 hours or less, the cache manager will favor recently created buckets. Also if a search looks for a specific time of day or specific tag, then the cache manager will be interested in the data that was around that same time range or logs that are usually recalled alongside the log you are searching for.
Why and When SmartStore?
SmartStore came about as being a cost effective solution for large Splunk environments with specific search criteria. It seems to perform best in an environment that does not run a lot of rare searches. It also likes environments that will run fairly predictive searches. Since this is a process that retrieves items from a giant object store bucket, there is a bit of a performance hit on it.
Make sure that your cost savings is worth your performance differential. One thing to keep in mind… fast is not the same for everyone and SLA’s can all be different. Remember the (somewhat modified) adage, “The bitterness of slow searches remains long after the sweet taste of low price is forgotten.”
Why and When
Now that we know the why, let’s take a look at the when:
- If the cost of cold storage is growing too high and searches aren’t run too much in them
- If you have a large indexer overhead due to HA
- When most of your searches are run over recent data
And what about the when not to’s?
- If you have a small deployment… Don’t overcomplicate it.
- If you run frequent rare searches. This will create a lot of calls to the S3 buckets and muck up your caching space.
- If you run long lookback searches… Again, think about the cache in this.
Some Things To Keep In Mind
There is no more SF / RF – Indexer data replication is now the responsibility of your infrastructure provider. Make sure your S3 storage platform has reputation of resilient storage.
You still need cache storage – There is still a cache tier that stores your initial data. This is tunable. You can adjust the size of these cache stores. Make sure you deploy infrastructure in a way that is easily expandable.
This is only available in Splunk 7.2 – focus on getting your upgrades there. Then let’s talk SmartStore strategy. Plus every indexer / sh / fw must be on the same code level and revision.
There are some features not supported – Tsidx reduction, Hadoop data roll, some bloom filter features, and the Data integrity control feature.
There are also some current restrictions – No DMA or Report acceleration, only available on indexer clusters, you cannot rollback from SmartStore once you go to it.
The old style is still here – If you have a large investment in a current Hot Warm Cold deployment, no worries! It’s still here! This is just a new option for you. There are a few different strategies you can have around deploying the new architecture. I’m sure your local Splunk or infrastructure vendor would love to help with this.
So how the heck do we size this? You’ll just have to wait for the next blog I guess. 🙂